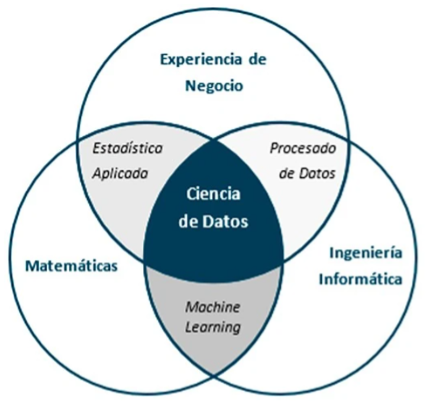
Análisis y Ciencia de Datos: Orígenes e historia
El origen de las actuales bases de datos se puede encontrar en el año 1884, en Nueva York, atribuyéndosele a Herman Hollerlith, quien inventó una máquina estadística de fichas perforadas para la realización del censo de Estados Unidos de 1890, siendo capaz de procesar los datos de 60 millones de ciudadanos en menos de 3 años. Esta máquina es considerada por algunos como el primer ordenador de la historia.
Con el paso del tiempo, la necesidad de almacenamiento y procesamiento de información fue creciendo, generando ya los primeros pasos de la analítica de datos, pues los volúmenes eran cada vez más grandes y se necesitaban mecanismos para ser procesados.
Durante los años 30 y 40 del siglo XX surgen grandes avances en la materia, considerando esta época también por algunos como el inicio de la era de la computación. Sin embargo, fue después de la II Guerra Mundial cuando la informática vivió sus primeros avances significativos.
Uno de los principales, donde ya se puede hablar de Procesamiento del Lenguaje Natural (PLN), es un experimento que tuvo lugar en 1954, llamado “Experimento Georgetown – IBM”, el cual ya muestra signos de Machine Learning o Aprendizaje Automático.

Experimento Georgetown – IBM
Dicho experimento consistía en una traducción automática del ruso al inglés, implementado mediante el sistema de tarjetas perforadas.

Ejemplo de tarjeta perforada
Este experimento no tuvo tanta repercusión como se esperaba inicialmente, pero marcó el punto de partida para que los gobiernos comenzasen a invertir en lingüística computacional.
Sin embargo, el año 1962 es donde realmente se considera que nació la ciencia de datos, gracias al matemático estadounidense John W. Tukey, quien es frecuentemente considerado como el “padre” de esta disciplina, ya que, entre sus labores de investigación, se encontraba la de hallar nuevas formas de analizar grandes conjuntos de datos para encontrar patrones y tendencias.
Tukey escribió, en ese mismo año, en “El futuro del análisis de Datos”, que el análisis de datos es intrínsicamente una ciencia empírica, pero no sería hasta 1974, donde el científico danés Peter Naur, ya lo definiría como una ciencia real, dejando la siguiente frase:
“Los datos son una representación de hechos o ideas de una manera formal que puede ser comunicada o manipulada por algún proceso”.
Otro de los puntos clave en el análisis de datos tuvo lugar en 1970, con la aparición, sin ninguna duda, del lenguaje que ha sentado las bases para las consultas en bases de datos: SQL.
SQL son las siglas de Structured Query Language, o, traducido al español, Lenguaje Estructurado de Consultas, el cual tuvo su origen en los laboratorios de IBM, teniendo su origen en la definición del modelo relacional de Bases de Datos, implementado por Edgar F. Codd, investigador de IBM.
Dicho modelo es consistente en la asociación de “claves” con varios datos y, para gestionar estas Bases de Datos, se ideó en IBM un lenguaje para gestionarlas, dando lugar a SEQUEL (Structured English Query Language), que posteriormente pasaría a ser SQL, tal cual lo conocemos hoy en día.
Continuando con la historia de cómo surgió y evolucionó la analítica y ciencia de datos, en 1977, el ISI (Institute of Scientific Information) establece la sección llamada “Asociación Internacional de la Computación Estadística” (IASC por sus siglas en Inglés), donde se describe a la ciencia de datos como una disciplina que combina campos como la estadística, los métodos científicos y el análisis de datos para extraer el valor de estos últimos”.
Puntualizar también que, durante la década de los 80, el avance de disciplinas como la ciencia y analítica de datos, así como el Machine Learning, se vio ralentizado principalmente debido a que los ordenadores no eran lo suficientemente potentes en aquella época, lo que provocaba que los profesionales en la materia tuviesen dificultades para programar.
Este hándicap fue resuelto en la década de los 90, donde la potencia de los ordenadores aumentó considerablemente, pudiéndose desarrollar nuevas técnicas de aprendizaje automático.
En esta década también surgió el “Análisis basado en Panel”, también conocido como “Reporting”, muy común entre los desarrolladores de Inteligencia de Negocio y Analistas de Datos.
Esta técnica consiste en las siguientes fases en lo que se refiere al trabajo con los datos:
- Recopilación
- Almacenamiento
- Procesado
- Análisis
- Visualización
Siendo este último punto donde se plasma el trabajo realizado, de una manera simplificada e intuitiva para que los usuarios lo puedan interpretar.
En 1994 nació una herramienta familiar entre los desarrolladores y Analistas, QlikView, la cual sirvió de inspiración a plataformas modernas como Tableau o Power BI. A continuación, una representación de cómo era la interfaz de QlikView en sus inicios:
Como conclusión, la Ciencia de datos tuvo su consolidación como una disciplina sólida e independiente en la primera década de este nuevo milenio, en parte gracias a William S. Cleveland, informático y estadístico estadounidense dedicado a la investigación de nuevos modelos de visualización de datos, quien en 2001 introdujo a la Ciencia de Datos como “una disciplina independiente de la estadística, definiéndola como un plan para ampliar las principales áreas del trabajo técnico del campo de las estadísticas, lo que implica un cambio sustancial y debe ser considerado una disciplina aparte.”
Desde el comienzo del siglo XXI, el avance de las nuevas tecnologías ha sido vertiginoso, poniendo el ejemplo de los teléfonos móviles, que en apenas 20 años han pasado de ser unos simples teléfonos sin necesidad de conexión a la red eléctrica a unos “mini-ordenadores portátiles”, o el avance imparable estos últimos años de la inteligencia artificial.
En conclusión, con este artículo se ha podido comprender cómo surgió la ciencia de datos y los pasos que ha ido teniendo desde sus inicios hasta nuestros días. Como suele decirse, todo tiene un principio y un final pero, viendo los avances tecnológicos actuales y, más aún, con el auge de la inteligencia artificial, el final está muy pero que muy lejano, por lo que podemos decir, sin duda, que ser analista y/o científico de datos es una de las profesiones del futuro.